NO.36 What is the main difference between AUTO LOADER and COPY INTO?
Explanation
Auto loader supports both directory listing and file notification but COPY INTO only supports di-rectory listing.
Auto loader file notification will automatically set up a notification service and queue service that subscribe to file events from the input directory in cloud object storage like Azure blob storage or S3. File notification mode is more performant and scalable for large input directories or a high volume of files.
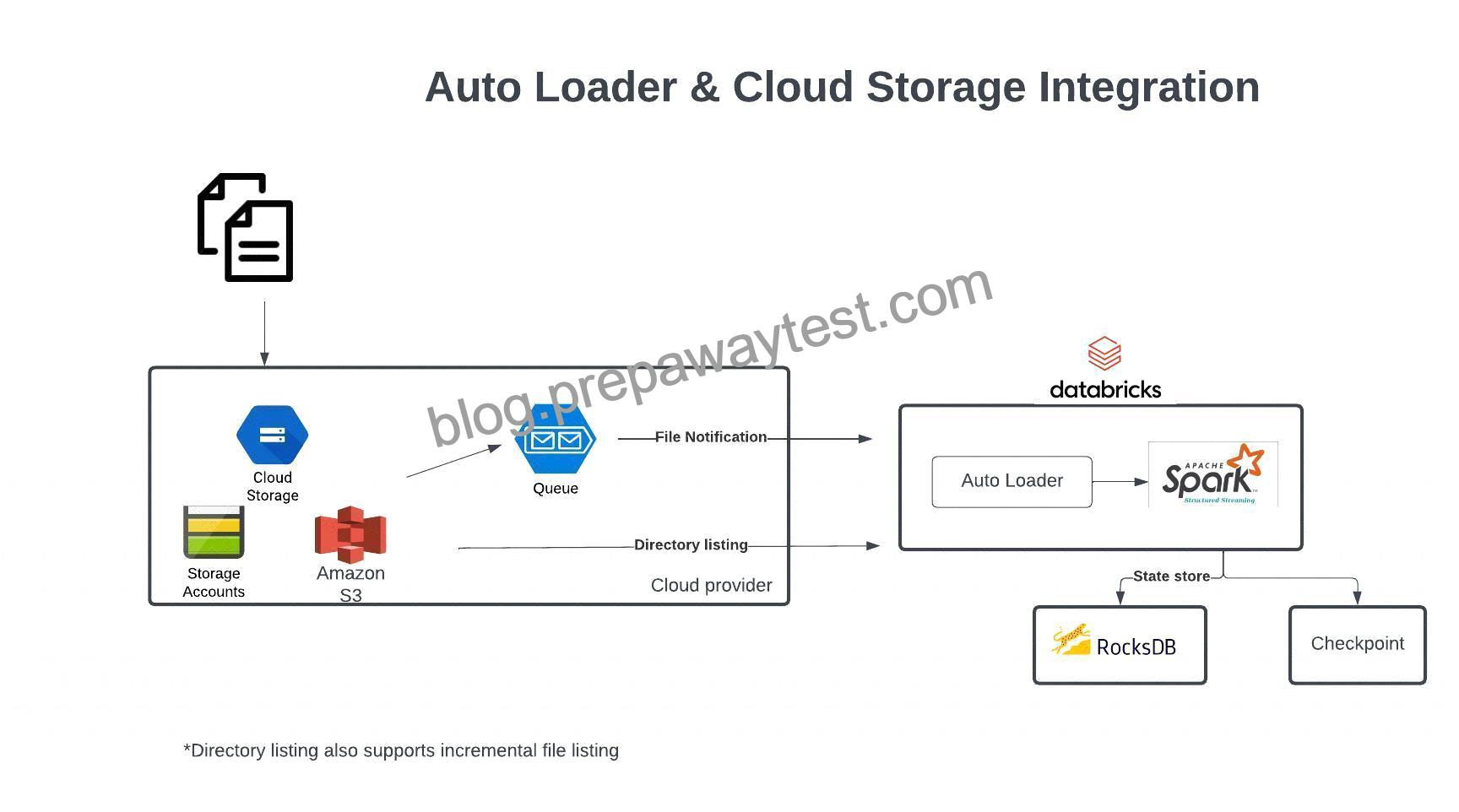
Auto Loader and Cloud Storage Integration
Auto Loader supports a couple of ways to ingest data incrementally
1.Directory listing – List Directory and maintain the state in RocksDB, supports incremental file listing
2.File notification – Uses a trigger+queue to store the file notification which can be later used to retrieve the file, unlike Directory listing File notification can scale up to millions of files per day.
[OPTIONAL]
Auto Loader vs COPY INTO?
Auto Loader
Auto Loader incrementally and efficiently processes new data files as they arrive in cloud storage without any additional setup. Auto Loader provides a new Structured Streaming source called cloudFiles. Given an input directory path on the cloud file storage, the cloudFiles source automatically processes new files as they arrive, with the option of also processing existing files in that directory.
When to use Auto Loader instead of the COPY INTO?
*You want to load data from a file location that contains files in the order of millions or higher. Auto Loader can discover files more efficiently than the COPY INTO SQL command and can split file processing into multiple batches.
*You do not plan to load subsets of previously uploaded files. With Auto Loader, it can be more difficult to reprocess subsets of files. However, you can use the COPY INTO SQL command to reload subsets of files while an Auto Loader stream is simultaneously running.
Auto loader file notification will automatically set up a notification service and queue service that subscribe to file events from the input directory in cloud object storage like Azure blob storage or S3. File notification mode is more performant and scalable for large input directories or a high volume of files.
Here are some additional notes on when to use COPY INTO vs Auto Loader
When to use COPY INTO
https://docs.databricks.com/delta/delta-ingest.html#copy-into-sql-command When to use Auto Loader
https://docs.databricks.com/delta/delta-ingest.html#auto-loader
